This post is part 1 of the "Advanced Scraping" series:
Static vs Dynamic
The Python documentation, wikipedia, and most blogs (including this one) use static content. When we request the URL, we get the final HTML returned to us. If that's the case, then a parser like BeautifulSoup is all you need. A short example of scraping a static page is demonstrated below. I have an overview of BeautifulSoup here.
A site with dynamic content is one where requesting the URL returns an incomplete HTML. The HTML includes Javascript for the browser to execute. Only once the Javascript finishes running is the HTML in its final state. This is common for sites that update frequently. For example, weather.com would use Javascript to look up the latest weather. An Amazon webpage would use Javascript to load the latest reviews from its database. If you use a parser on a dynamically generated page, you get a skeleton of the page with the unexecuted javascript on it.
This post will outline different strategies for scraping dynamic pages.
An example of scraping a static page
Let's start with an example of scraping a static page. This code demonstrates how to get the Introduction section of the Python style guide, PEP8:
import requests
from bs4 import BeautifulSoup # install with 'pip install BeautifulSoup4'
url = 'https://www.python.org/dev/peps/pep-0008/'
r = requests.get(url)
soup = BeautifulSoup(r.text, 'html.parser')
# By inspecting the HTML in our browser, we find the introduction
# is contained in <div id='introduction'> ..... </div>
intro_div = soup.find(id='introduction')
print(intro_div.text)
This prints
Introduction This document gives coding conventions for the Python code comprising the standard library in the main Python distribution. Please see the companion informational PEP describing style guidelines for the C code in the C implementation of Python [1]. ....
Volia! If all you have is a static page, you are done!
The straightforward way to scrape a dynamic page
The easiest way of scraping a dynamic page is to actually execute the javascript, and allow it to alter the HTML to finish the page. We can pass the rendered (i.e. finalized) HTML to python, and use the same parsing techniques we used on static sites. The Python module Selenium allows us to control a browser directly from Python. The steps to Parse a dynamic page using Selenium are:
- Initialize a driver (a Python object that controls a browser window)
- Direct the driver to the URL we want to scrape.
- Wait for the driver to finish executing the javascript, and changing the HTML. The driver is typically a Chrome driver, so the page is treated the same way as if you were visiting it in Chrome.
- Use
driver.page_sourceto get the HTML as it appears after javascript has rendered it. - Use a parser on the returned HTML
The website https://webscraper.io has some fake pages to test scraping on. Let's use it on the page https://www.webscraper.io/test-sites/e-commerce/ajax/computers/laptops to get the product name and the price for the six items listed on the first page. These are randomly generated; at the time of writing the products were an Asus VivoBook (295.99), two Prestigio SmartBs (299 each), an Acer Aspire ES1 (306.99), and two Lenovo V110s (322 and 356).
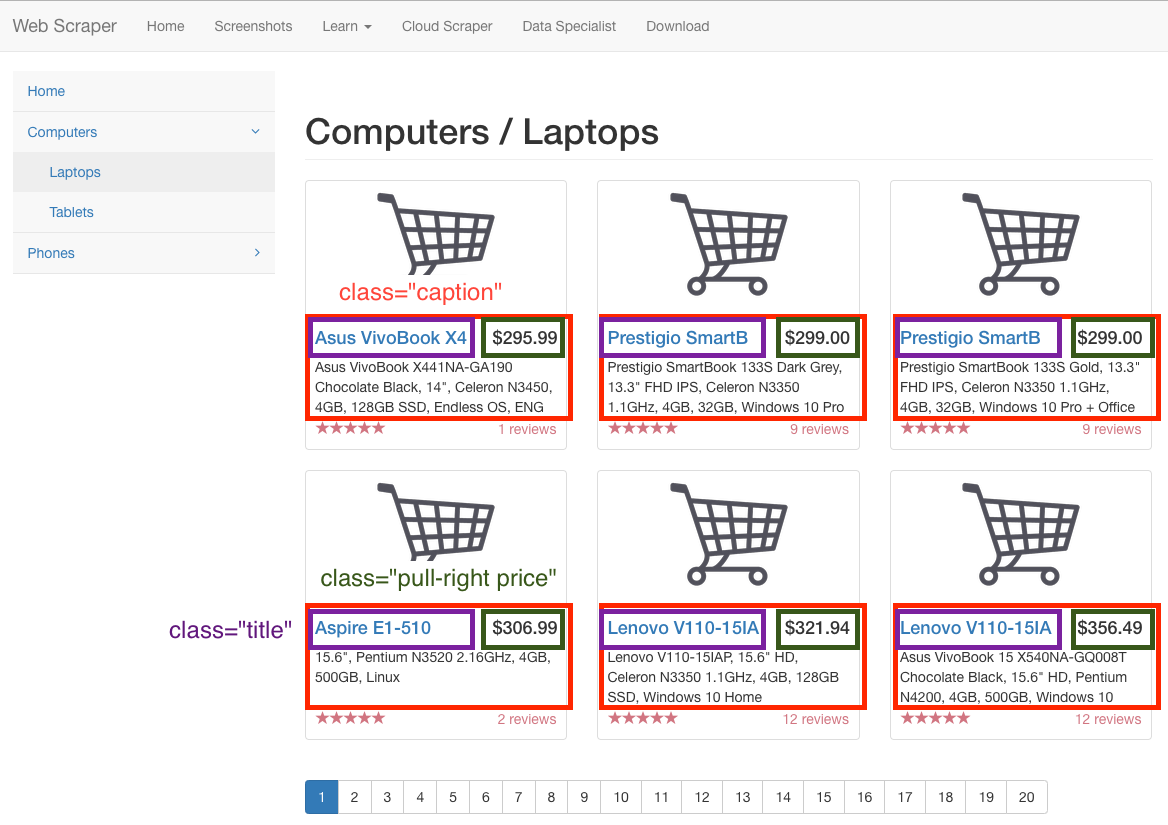
Once the HTML has been by Selenium, each item has a div with class caption that contains the information we want. The product name is in a subdiv with class title, and the price is in a subdiv with the classes pull-right and price. Here is code for scraping the product names and prices:
from bs4 import BeautifulSoup
from selenium import webdriver
import time
url = 'https://www.webscraper.io/test-sites/e-commerce/ajax/computers/laptops'
# Change argument to the location you installed the chrome driver
# (see selenium installation instructions, or get the driver for your
# system from https://sites.google.com/a/chromium.org/chromedriver/downloads)
driver = webdriver.Chrome('/Users/damien/Applications/chromedriver')
driver.get(url)
# Give the javascript time to render
time.sleep(1)
# Now we have the page, let BeautifulSoup do the rest!
soup = BeautifulSoup(driver.page_source)
# The text containing title and price are in a
# div with class caption.
for caption in soup.find_all(class_='caption'):
product_name = caption.find(class_='title').text
price = caption.find(class_='pull-right price').text
print(product_name, price)
Trying scraping a dynamic site using requests
What would happen if we tried to load this e-commerce site using requests? That is, what if we didn't know it was a dynamic site?
The html we get out can be a little difficult to read directly. If you are using a terminal, then you can save the results from r.html to a file and then load it in a browser. If you are using a Jupyter notebook, you can actually use a neat trick to render the output in your browser:
# We will try and render what requests returns from https://www.webscraper.io/test-sites/e-commerce/allinone
# without running javascript first
import requests
from IPython.display import HTML
url = 'https://www.webscraper.io/test-sites/e-commerce/ajax/computers/laptops'
r = requests.get(url)
HTML(r.text)
The output in the notebook is an empty list, because javascript hasn't generated the items yet.

Alternatives to Selenium
Using Selenium is an (almost) sure-fire way of being able to generate any of the dynamic content that you need, because the pages are actually visited by a browser (albeit one controlled by Python rather than you). If you can see it while browsing, Selenium will be able to see it as well.
There are some drawbacks to using Selenium over pure requests:
- It's slow.
We have to wait for pages to render, rather than just grabbing the data we want.
- We have to download images and assets, using bandwidth
Related to the previous point, even if we are just parsing for text, our browser will download all ads and images on the site.
- Chrome takes a lot of memory
When scraping, we might want to have parallel scrapers running (e.g. one for each category of items on an e-commerce site) to allow us to finish faster. If we use Selenium, we will have to have enough memory to have multiple copies running.
- We might not need to parse
Often sites will make API calls to get the data in a nicely formatted JSON object, which is then processed by Javascript into HTML entities. When using a parser such as BeautifulSoup, we are reading in the HTML entities, and trying to reconstruct the original data. It would be a lot slicker (and less error prone) if we are able to get the JSON objects directly.
- Selenium (like parsing) is often tedious and error-prone
The bad news for using the alternative methods is that there are so many different ways of loading data that no single technique is guaranteed to work. The biggest advantage Selenium has is that it uses a browser, and with enough care, should be indistinguishable from you browsing the web yourself.
Other techniques
This is the first in a series of articles that will look at other techniques to get data from dynamic webpages. Because scraping requires a custom approach to each site we scrape, each technique will be presented as a case study. The examples will be detailed enough to enable you to try the technique on other sites.
| Technique | Description | Examples |
|---|---|---|
| Scheme or Opengraph MetaData | OpenGraph is a standard for allowing sites like Facebook to easily find what your page is 'about'. We can scrape the relevant data directly from these tags | ??? Need example ??? |
| JSON for Linking Data | This is a standard for putting JSON inside Javascript tags | Yelp |
| XHR | Use the same API requests that the browser does to get the data | Sephora lipsticks, Apple jobs |
Selenium summary
The short list of pros and cons for using Selenium to scrape dynamic sites.
| Pros | Cons |
|---|---|
| * Will work | * Slow |
| * Bandwidth and memory intensive | |
| * Requires error-prone parsing |